
Free demo before buying our products
It everyone knows that actions speak louder than words, we know that let you have a try by yourself is the most effective way to proof how useful our Associate-Developer-Apache-Spark-3.5 exam dumps materials are, so we provide free demo for our customers before you make a decision. The demo is a little part of the contents in our Associate-Developer-Apache-Spark-3.5 test braindumps: Databricks Certified Associate Developer for Apache Spark 3.5 - Python, through which you can understand why our exam study materials are so popular in many countries. In addition, in order to meet the various demands of different people you can find three different versions of the Associate-Developer-Apache-Spark-3.5 exam dumps materials on our website, namely that PDF Version, PC Test Engine and Online Test Engine, you can choose any one version of Associate-Developer-Apache-Spark-3.5 exam materials or the package as you like. We will spare no effort to help you until you pass exam.
As we all know, it is a must for Databricks workers to pass the exam in the shortest time if they want to get the certification. However, the exam is very difficult for the majority of workers normally, if you are still worried about your exam, it is really lucky for you to click into our website. Our company has been engaged in compiling the Associate-Developer-Apache-Spark-3.5 test braindumps: Databricks Certified Associate Developer for Apache Spark 3.5 - Python for nearly ten years, and we are proud to introduce our achievements of our exam products to you. Our Associate-Developer-Apache-Spark-3.5 exam dumps materials are widely praised by all of our buyers all over the world and our company has become the leader in this field and can be surpassed. Furthermore, although our Associate-Developer-Apache-Spark-3.5 exam dumps materials are the best in this field, in order to help more people, the price of our product is reasonable in the market. So you can get the best Associate-Developer-Apache-Spark-3.5 test braindumps: Databricks Certified Associate Developer for Apache Spark 3.5 - Python for the exam casually with a favorable price only in our website, just as the old saying goes:" Opportunity for those who are prepared" Just take this chance and please believe that success lies ahead.

Professional & excellent after-sale service
There is another important reason why our company can be the leader in this field: we have always attached great importance to the after-sale service of purchasing Associate-Developer-Apache-Spark-3.5 test braindumps: Databricks Certified Associate Developer for Apache Spark 3.5 - Python for our buyers, and we think highly of the satisfaction of customers as an inspiration to us. We will provide the after-sale service for 7/24 hours online the whole year so that we contact with our customers and reply their email or online news about Associate-Developer-Apache-Spark-3.5 exam dumps materials from different countries. We will seldom miss even any opportunity to reply our customers' questions and advice about Associate-Developer-Apache-Spark-3.5 study guide materials as well as solve their problems about the Databricks Associate-Developer-Apache-Spark-3.5 exam in time. All of the after-sale service staffs have received the professional training before they become regular employees in our company, we assure that our workers are professional enough to answer your questions and help you to solve your problems excellently. So if you have any problem about Associate-Developer-Apache-Spark-3.5 study materials: Databricks Certified Associate Developer for Apache Spark 3.5 - Python, please don't hesitate to contact with our after-service workers any time as you like.
After purchase, Instant Download: Upon successful payment, Our systems will automatically send the product you have purchased to your mailbox by email. (If not received within 12 hours, please contact us. Note: don't forget to check your spam.)
Databricks Certified Associate Developer for Apache Spark 3.5 - Python Sample Questions:
1. Given the code fragment: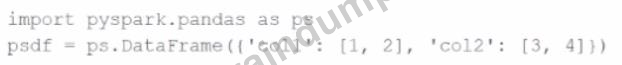
import pyspark.pandas as ps
psdf = ps.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
A) psdf.to_dataframe()
B) psdf.to_pandas()
C) psdf.to_pyspark()
D) psdf.to_spark()
2. 40 of 55.
A developer wants to refactor older Spark code to take advantage of built-in functions introduced in Spark 3.5.
The original code:
from pyspark.sql import functions as F
min_price = 110.50
result_df = prices_df.filter(F.col("price") > min_price).agg(F.count("*")) Which code block should the developer use to refactor the code?
A) result_df = prices_df.filter(F.lit(min_price) > F.col("price")).count()
B) result_df = prices_df.where(F.lit("price") > min_price).groupBy().count()
C) result_df = prices_df.filter(F.col("price") > F.lit(min_price)).agg(F.count("*"))
D) result_df = prices_df.withColumn("valid_price", when(col("price") > F.lit(min_price), True))
3. An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:
def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
A) Convert the Pandas UDF from a Series → Series UDF to an Iterator[Series] → Iterator[Series] UDF
B) Convert the Pandas UDF to a PySpark UDF
C) Convert the Pandas UDF from a Series → Series UDF to a Series → Scalar UDF
D) Run the in_spanish_inner() function in a mapInPandas() function call
4. A developer is trying to join two tables, sales.purchases_fct and sales.customer_dim, using the following code:
fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid')) The developer has discovered that customers in the purchases_fct table that do not exist in the customer_dim table are being dropped from the joined table.
Which change should be made to the code to stop these customer records from being dropped?
A) fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid'), 'right_outer')
B) fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid'), 'left')
C) fact_df = cust_df.join(purch_df, F.col('customer_id') == F.col('custid'))
D) fact_df = purch_df.join(cust_df, F.col('cust_id') == F.col('customer_id'))
5. 13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
A) regions_dict = regions.select("region_id", "region_name").take(3)
B) regions_dict = dict(regions.orderBy("region_id").limit(3).rdd.map(lambda x: (x.region_id, x.region_name)).collect())
C) regions_dict = dict(regions.select("region_id", "region_name").rdd.collect())
D) regions_dict = dict(regions.take(3))
Solutions:
| Question # 1 Answer: D | Question # 2 Answer: C | Question # 3 Answer: A | Question # 4 Answer: B | Question # 5 Answer: B |
 Bert
Bert 
 Ron
Ron 
 Tyrone
Tyrone  Dawn
Dawn 
 Jane
Jane  Sebastiane
Sebastiane  Juliet
Juliet  Adelaide
Adelaide  Ogden
Ogden 